Microsoft Azureコラム
Writer:手戸 蒼唯(てど あおい)
ビッグデータの3V、5Vとは?保有するビッグデータを見直してみよう!
データは企業の競争力を左右する重要な資産です。また今日では、ビッグデータと呼ばれる膨大なデータ量が扱われるようになってきました。製造業においても、IoTの普及にともない膨大なデータが生成・活用されています。ビッグデータはそのデータ量にのみ注目されがちですが、保有しているビッグデータの特徴を理解したうえで、事業に活用することが必要です。
本記事では、ビッグデータを特徴づける3つのV(Volume, Velocity, Variety)について詳しく解説し、さらに近年注目されている2つのV(Veracity, Value)を加えた5Vの概念まで踏み込んで説明します。これらの要素を理解することで、製造業におけるビッグデータ活用の可能性をより引き出していきましょう。
ネクストステップにおすすめ
製造業におけるデータ活用の課題、新しいデータ活用基盤の求められる要件や導入ステップを解説します。


ビッグデータの3V、5Vはビッグデータを定義づけるもの
ビッグデータは、従来のデータ処理システムでは扱いきれない大規模かつ複雑なデータセットを指します。企業の戦略的意思決定や新たな価値創造に活用されますが、総務省の「情報通信白書」によると、ビッグデータは以下のように定義されています。
「ビッグデータとは、事業に役立つ知見を導出するためのデータであり、一般的に Volume(量)、Velocity(速度)、Variety(多様性)、の3Vに加え、Veracity(正確性)と Value(価値)を加えた5Vで説明されることが多い。」
ここからは、製造業でよく扱われるデータ例を取り上げながら、軸にビックデータを特徴づける3V、5Vについて深掘りしていきます。
出典:総務省「情報通信白書平成29年版」
5Vそれぞれの特徴を説明した図
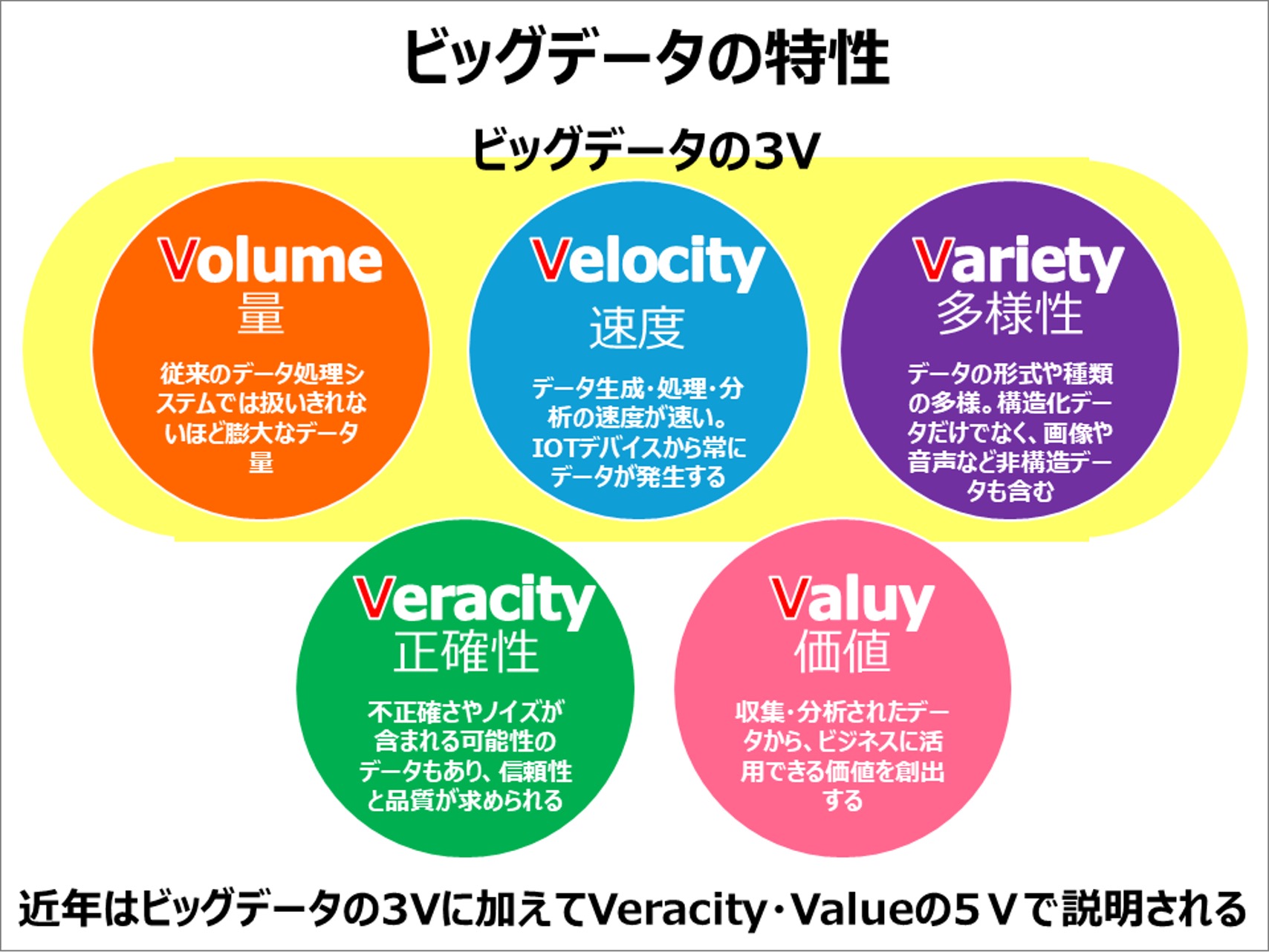
Volume(量):データの規模
ビッグデータの「Volume(量)」は、従来のデータ処理システムでは扱いきれないほどの膨大なデータ量を指します。この「量」は、単にデータの大きさだけでなく、データポイントの数、生成速度、そして処理の複雑さも含む概念です。
製造業を例に取ると、工場内の数千ものセンサーが1秒ごとにデータを生成し、それが24時間365日続くことを想像してみてください。このデータ量は、従来のスプレッドシートやデータベースでは到底扱えないほどの規模になります。
ビッグデータのVolumeの特徴
ビッグデータの「Volume」(量)は、データの大規模性を表す特徴です。具体的には以下のような点が挙げられます。
- 指数関数的な成長:データ量が急速に、そして継続的に増加する
- 多様なソースからの統合:複数のシステムやデバイスからのデータが集約される
- 高度な処理能力の要求:データの保存、処理、分析に特殊な技術が必要となる
このような巨大なデータ量を扱うことで、より精密な分析や予測が可能になり、ビジネスに革新的な洞察をもたらす可能性が広がります。
ビッグデータにおける「大量」の定義と具体例
ビッグデータにおける「大量」とは、テラバイト(TB)、ペタバイト(PB)、さらにはエクサバイト(EB)級のデータ量を指します。これは従来のギガバイト(GB)単位のデータ処理とは桁違いの規模です。
例えば、ある自動車製造ラインでは、以下のようなデータが日々生成されています。
- 1台の車の組立てに使用されるセンサー数:約5,000個
- 1つのセンサーが1秒間に生成するデータポイント:10個
- 1日の生産台数:1,000台
- 1日の稼働時間:16時間
ここれらの数字から計算すると、1日あたりのデータポイント数は以下のようになります: 5,000 × 10 × 3,600秒 × 16時間 × 1,000台 = 28,800,000,000,000(28.8兆)データポイント
このデータ量は、1日あたり約300テラバイトに相当します。
この量を視覚化すると、300テラバイトは約6,000万枚の高解像度デジタル写真、または約15万時間のHD動画に相当します。つまり、1日の製造ラインデータは、17年分の連続HD動画再生に匹敵する膨大な量となります。
Velocity(速度):データ処理のリアルタイム性
ビッグデータの「Velocity(速度)」は、データが生成、処理、分析される速度を指します。この概念は、従来のバッチ処理型のデータ分析とは大きく異なり、リアルタイムまたはニアリアルタイムでのデータ処理を可能にします。
製造業を例にとると、生産ラインの各センサーが1秒間に数十回のデータを送信し、それをミリ秒単位で処理して即座に判断や制御に反映させるようなケースが考えられます。この高速なデータ処理により、品質管理、設備保全、在庫管理などにおいて、即時の対応や予測が可能になります。
ビッグデータのVelocityの特徴
- ビッグデータの「Velocity」(速度)は、データの生成、処理、分析の速さを表す特徴です。具体的には以下のような点が挙げられます。リアルタイム分析:データをリアルタイムで処理し、即座に洞察を得る
- 即時対応:異常や変化を瞬時に検知し、迅速に対応する
- 予測分析:高速なデータ処理により、より精度の高い予測が可能になる
このような高速データ処理は、ビジネスの意思決定スピードを劇的に向上させ、競争優位性を高める重要な要素となっています。
リアルタイムデータ処理の重要性
製造業におけるリアルタイムデータ処理の重要性は、以下のような点にあります。
品質管理:製造プロセスの異常を即座に検知し、不良品の発生を防ぐ
設備保全:機械の状態をリアルタイムでモニタリングし、故障を予防する
在庫管理:需要の変化にリアルタイムで対応し、適正在庫を維持する
例えば食品メーカーであれば、商品の品質に直結する要素(たとえば温度・湿度)の監視が重要です。リアルタイム監視を行うことで、問題が起きる前に対策を講じられるため、不良品の減少や品質向上が可能となるでしょう。
Variety(多様性):データソースの多様性
ビッグデータの「Variety(多様性)」は、データの形式や種類の多様さを指します。従来のデータ分析では主に構造化データを扱っていましたが、ビッグデータの世界では構造化データ、半構造化データ、非構造化データなど、さまざまな種類のデータを統合して分析します。
製造業を例にとると、生産ラインのセンサーデータ(構造化)、機械の稼働音(非構造化)、作業員の行動ログ(半構造化)など、多様なデータを組み合わせて分析することで、より深い洞察を得ることができます。この多様性により、単一のデータソースでは見えなかった相関関係や傾向を発見できる可能性が広がります。
ビッグデータのVarietyの特徴
- ビッグデータの「Variety」(多様性)は、データの形式や種類の多様さを表す特徴です。この多様性は以下のような側面を持っています。データ形式の多様性:構造化、半構造化、非構造化データ
- データソースの多様性:内部・外部ソース、IoTデバイス
- 時間的・空間的多様性:リアルタイム、履歴、地理的データ
- 粒度の多様性:集計データと詳細データ
この多様性により、包括的な分析、新たな相関関係の発見、イノベーションの促進が可能になります。
構造化データと非構造化データの特徴と違い
ビッグデータは、大きく分けて構造化データと非構造化データに分類されます。
- 構造化データ:明確に定義されたスキーマを持つデータ
- 例:生産量、在庫数、売上高など
- 特徴:従来のリレーショナルデータベースで扱いやすい - 非構造化データ:事前に定義されたデータモデルを持たないデータ
- 例:テキストデータ、画像、音声、動画など
- 特徴:分析にAIや機械学習の技術が必要
製造業では、センサーデータ(構造化)と品質検査画像(非構造化)のように、両方のタイプのデータを扱う必要があります。例えば、ある自動車メーカーでは、生産ラインの数値データ(構造化)と製品の外観検査画像(非構造化)を組み合わせて分析することで、品質管理の精度を大幅に向上させています。
Veracity(正確性):データの正確性・信頼性
ビッグデータの「Veracity(正確性)」は、データの信頼性と品質を指します。膨大なデータ量と多様なソースから生成されるビッグデータには、不正確さやノイズが含まれる可能性が高く、これらが分析結果の信頼性に大きく影響します
製造業を例にとると、センサーの誤作動、人為的な入力ミス、通信エラーなどにより、不正確なデータが混入する可能性があります。こうしたデータの不確実性を理解し、適切に管理することが、ビッグデータ分析の成功には不可欠です。
ビッグデータのVeracityの特徴
- ビッグデータの「Veracity」(正確性)は、データの信頼性と品質を表す特徴です。この特性は以下のような側面を持っています。分析精度の向上:高品質なデータによる信頼性の高い分析結果
- リスク軽減:不正確なデータに基づく誤った意思決定の防止
- コンプライアンス:データの正確性に関する法的要件への対応
データの正確性を確保することで、ビッグデータ分析の価値を最大化し、信頼性の高い意思決定を行うことが可能になります。
データの品質管理と信頼性確保の方法
データの品質管理と信頼性確保には、以下のような方法があります。
データガバナンスの確立:組織全体でのデータ管理ポリシーの策定
データプロファイリング:データの特性や傾向を把握
データ品質スコアリング:データの正確性や完全性を数値化
マスターデータマネジメント(MDM):重要データの一元管理
データクレンジングとデータエンリッチメントによるVeracityの向上
さらにデータクレンジングを行うことで、ビッグデータのVeracityを向上させることも可能です。 データクレンジングとは、不正確なデータを修正・削除し、データの品質を向上させることです。また、データエンリッチメントは、外部データを追加してデータの価値を高める手法です。主なプロセスは以下となります。
- 重複データの削除
- 欠損値の処理(補完または削除)
- 形式の標準化
- 外部データの統合
Value(価値):データが持つ価値創出の可能性
ビッグデータの「Value(価値)」は、収集・分析されたデータから実際のビジネス価値を創出することを意味します。これは、ビッグデータの5Vの中で最も重要な要素と言えるでしょう。単にデータを収集・分析するだけでなく、そこから得られた洞察を実際のビジネス改善や新しい価値創造に結びつけることこそが、ビックデータの活用の真髄ともいえるためです。
製造業を例にとると、生産ラインのセンサーデータ分析から得られた洞察を基に、生産プロセスを最適化し、不良品率を低減させたり、予知保全システムを構築して設備のダウンタイムを最小化したりすることが考えられます。また、顧客の使用データ分析から新製品開発のヒントを得るなど、データを起点としたさまざまな価値創造が可能になります。
ビッグデータのValueの特徴
ビッグデータの「Value(価値)」は、収集・分析されたデータから実際のビジネス価値を創出する能力を表す特徴です。この特性は以下のような側面を持っています。
- 実用性:理論的な洞察だけでなく、具体的なビジネス成果に結びつく実践的な価値を生み出す能力。
- 測定可能性:ROIなど具体的な指標で価値を定量化し、評価することができる特性。
- 多様性:コスト削減、効率化、新規ビジネス創出など、様々な形態で価値を生み出す可能性。
- 継続性:データ分析と価値創出の継続的なサイクルを確立し、持続的な価値を生み出す能力。
- 革新性:既存のビジネスモデルや業務プロセスを根本から変革する可能性を持つ特性。
Valueの実現により、企業は競争力を強化して新たな成長機会を獲得することが可能になります。
データから洞察を得るための手順
データから価値を創出するプロセスは、一般的に以下の手順で行います。
- データ収集:さまざまなソースからデータを収集
- データ処理:クレンジング、統合、変換
- データ分析:統計分析、機械学習、深層学習など
- 洞察の導出:分析結果の解釈と意味づけ
- 行動:洞察に基づいた意思決定と実行
例えば製造業では、このプロセスを通じて製品の不良率の削減が可能となるでしょう。具体的には以下のような流れで行います。
- データ収集:製造ラインの各工程からセンサーデータを収集
- データ処理:ノイズの除去、欠損値の補完、データの標準化
- データ分析:機械学習モデルを用いた不良品発生要因の分析
- 洞察の導出:特定の温度・湿度条件下で不良品が増加することを発見
- 行動:製造環境の最適化と予防的メンテナンスの実施
こうした取り組みで不良品率が減少することで、年間の損失額を削減することが可能となります。
ビジネス価値を創出したケーススタディの紹介
製造業におけるビッグデータ活用は、さまざまな形でビジネス価値を創出しています。以下にデータ活用からビジネス価値の創出を行ったケーススタディを紹介します。
- 予知保全
例えば工作機械メーカーであれば、IoTセンサーからのデータを分析し、機械の故障を事前に予測するシステムを構築が可能となります。この結果、計画外のダウンタイムを減少させることで、生産性の向上に繋がります。 - サプライチェーン最適化
大手電機メーカーならば、需要予測、在庫データ、物流データを統合分析し、サプライチェーンの最適化が実現可能です。その結果、在庫コストが削減され、納期の遵守率が向上します。 - 製品開発の効率化
自動車メーカーであれば、顧客の使用データ、SNSでの評価、競合情報などのビッグデータを活用して製品開発プロセスを改善に活用できます。これにより、新モデルの開発期間の短縮や、初期品質問題の削減が可能となるでしょう。
ビッグデータ活用は製造業に多大な価値をもたらす可能性を示しています。
データ駆動型(データドリブン)意思決定の重要性とメリット
ビッグデータの真の価値は、それをもととした意思決定にあります。従来の経験や直感に頼る方法から、データに基づく客観的な意思決定へと移行することで、ビジネスの効率と効果を大幅に向上させることができます。
この新しいアプローチは「データ駆動型意思決定」(Data-Driven Decision Making, DDDM)と呼ばれ、以下のような利点があります。
- 客観性の向上:個人の偏見や思い込みを排除し、事実に基づく判断が可能
例:製造業では、品質管理担当者の主観的判断に頼っていた検査プロセスを、データ分析に基づく自動検査システムに置き換えて、不良品の検出率を向上。 - 迅速な対応:リアルタイムデータに基づく素早い判断と行動
例:大手自動車メーカーが生産ラインにIoTセンサーを導入し、異常を即座に検知・対応するシステムを構築。その結果、ダウンタイムを60%削減。 - 予測精度の向上:大量のデータと高度な分析技術による精密な予測
例:ある電子機器メーカーが過去の販売データ、経済指標、SNSの評判分析を組み合わせた需要予測モデルを開発。在庫回転率を40%改善。 - リスク管理の強化:データに基づく慎重な判断によるリスクの最小化
例:化学プラントにおいて、センサーデータと気象データを組み合わせた予知保全システムを導入。設備故障による緊急停止が年間5件から1件に減少。
このように、ビッグデータを活用したデータ駆動型の意思決定は、ビジネスのさまざまな側面で具体的な価値を生み出し、企業の競争力強化に貢献します。
5Vの相互関係と重要性
5Vの各要素は独立したものではなく、相互に影響し合っています。これらの要素をバランス良く考慮することが、効果的なビッグデータ活用の鍵となるため、相互関係を理解しておくことが重要です。
各要素のバランスとトレードオフ
5Vの要素間には、しばしばトレードオフの関係が存在します。具体的には以下が挙げられます。
- Volume vs Velocity:データ量が増えると処理速度が低下する可能性がある
- Variety vs Veracity:多様なデータソースを統合すると、データの正確性が損なわれる可能性がある
- Velocity vs Value:リアルタイム性を追求するあまり、深い分析ができず価値が低下する可能性がある
これらのトレードオフを適切に管理し、バランスを取ることが重要です。
5Vの関係性を説明した図
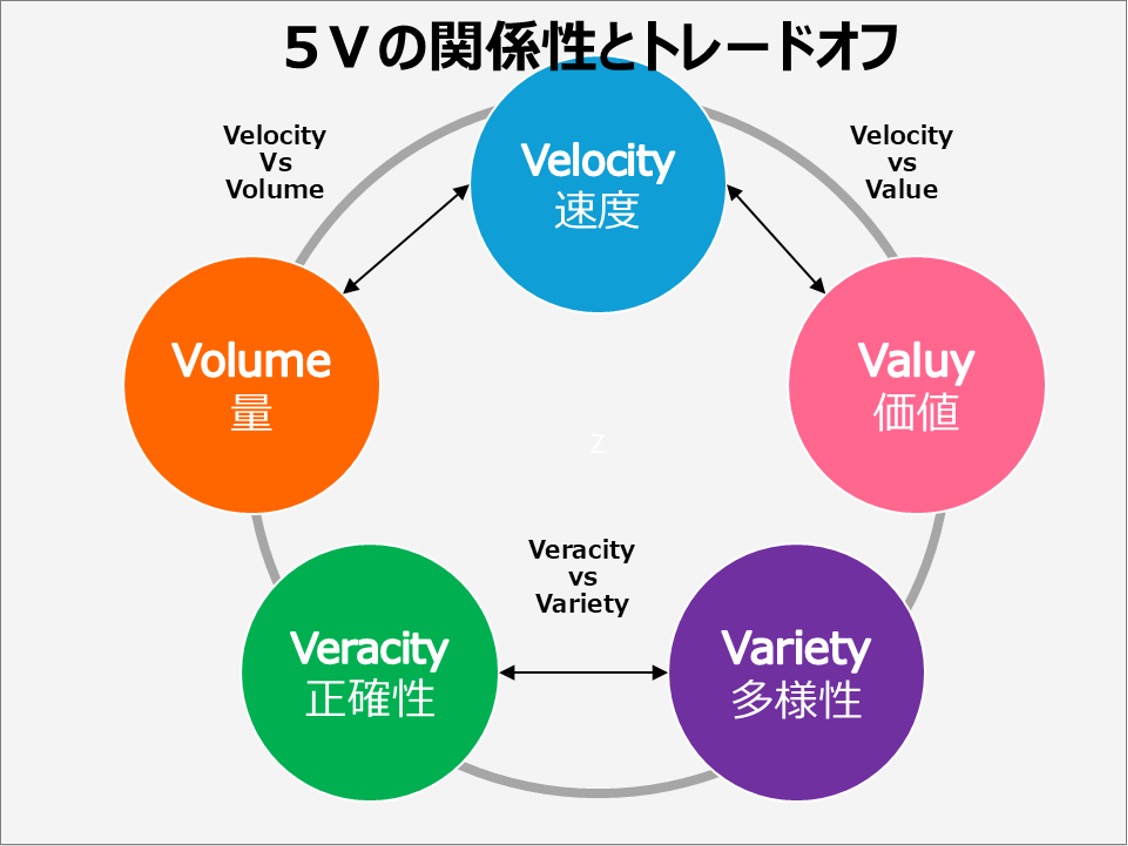
ビッグデータの5Vを考慮したデータ戦略の立て方
効果的なデータ戦略を立てるためには、保有しているビッグデータの5Vの状態を認識することが重要です。
以下のステップを参考にしてください。
- 目的の明確化:ビッグデータ活用の目的を明確にする
- データの棚卸し:現状のデータ資産を5Vの観点から評価する
- ギャップ分析:目的達成に必要なデータと現状のギャップを特定する
- 技術選定:5Vのバランスを考慮し、適切な技術やツールを選択する
- 人材育成:データサイエンティストやデータエンジニアの育成・採用計画を立てる
- ガバナンス体制の構築:データの品質管理やセキュリティ対策を含むガバナンス体制を整備する
- 段階的実施:小規模なプロジェクトから始め、徐々に拡大していく
ビックデータの将来展望と新たなトレンド
更なる技術の発展に伴い、ビッグデータの概念や特徴づける観点も急速に進化し続けています。これまで解説した5Vに加えて、新たなトレンドを把握し、積極的に取り入れていくことが必要でしょう。
新たなVの可能性(Visualization, Variabilityなど)
5Vの概念に加えて、新たなVが提唱されています。
Visualization(可視化):複雑なデータを直感的に理解できるよう視覚化する能力
Variability(可変性):データの意味や構造が時間とともに変化する特性
Viscosity(粘性):データの流動性と使いやすさを表す指標
これらの新しい概念は、ビッグデータをより包括的に理解し、効果的に活用するための視点を提供します。
関連資料:製造現場は可視化でこう変わる!!
技術の進化が5Vに与える影響
さらに技術の進歩は、5Vの各要素に大きな影響を与えています。
- Volume:5G、IoTの普及により、データ量はさらに増大
- Velocity:エッジコンピューティング、5Gにより、リアルタイム処理がより高速に
- Variety:AIによる非構造化データの解析能力の向上
- Veracity:ブロックチェーン技術によるデータの信頼性向上
- Value:AIと人間の協調による新たな価値創造
例えば、5Gとエッジコンピューティングの組み合わせにより、工場内の全センサーデータをミリ秒単位でリアルタイム処理することが可能になります。
ビッグデータ活用で製造業の未来を拓く
ビッグデータの5V(Volume, Velocity, Variety, Veracity, Value)は、製造業におけるデータ活用の本質を表現しています。膨大な量のデータを、高速で処理し、多様なソースから統合し、その正確性を確保しながら、実際のビジネス価値へと変換する。この一連のプロセスを効果的に実現することが、製造業のデジタルトランスフォーメーションの鍵となります。
しかし、これらの要素のバランスを取りながら、最適に管理することは、決して容易ではありません。そこで重要となるのが、統合的なデータプラットフォームの活用です。
Microsoft Fabricは、これらの課題に対応する包括的なソリューションを提供します。データの収集から保存、処理、分析、可視化まで、一気通貫で管理できるこのプラットフォームは、製造業のビッグデータ活用を強力に支援します。詳細については、「AI時代のデータ活用基盤『Microsoft Fabric』」のページをご覧ください。
ビッグデータ3つのVに関するFAQ
Q. ビッグデータの3Vと5Vの違いは何ですか?
3V(Volume, Velocity, Variety)は元々のビッグデータの特徴を表す概念で、5Vはそれに Veracity(正確性)とValue(価値)を加えた拡張概念です。
Q. 製造業でビッグデータを活用する際の最大の課題は何ですか?
データの統合と品質管理が大きな課題です。多様なソースからのデータを統合し、その正確性を確保することが重要です。
Q. ビッグデータ分析に必要なスキルは何ですか?
データサイエンス、統計学、プログラミング、ドメイン知識が重要です。また、データの可視化やコミュニケーション能力も求められます。
Q. 中小製造業でもビッグデータを活用できますか?
はい、可能です。クラウドサービスを利用することで、初期投資を抑えつつビッグデータ分析を始めることができます。
Q. ビッグデータ活用における個人情報保護の課題はどうすれば良いですか?
データの匿名化、暗号化、アクセス制御など、適切なセキュリティ対策を講じることが重要です。また、関連法規を遵守する必要があります。
ネクストステップにおすすめ
製造業におけるデータ活用の課題、新しいデータ活用基盤の求められる要件や導入ステップを解説します。